Index thật tuyệt vời, nó có thể giúp câu truy vấn chạy nhanh hơn rất nhiều lần. Nếu bạn chưa biết làm thế nào nó có thể làm được điều đó thì hãy đọc phần 1 của loạt bài viết về index này. Với index trong phần 1 này chúng ta sẽ dễ dàng tìm kiếm một nhân viên bất kì theo giá trị cột ID.
Giới hạn của clustered index
Bây giờ, nếu câu truy vấn muốn tìm nhân viên theo MaNV thì thế nào? liệu index CIX_NhanVien ở phần trước có giúp được không?
SELECT ID, MaNV, TTT FROM NhanVien WHERE MaNV = 'KT001'
Hiển nhiên là không thể, index đó được xây dựng dựa trên giá trị cột ID, nên chỉ có thể tìm theo ID. Nếu bạn muốn tìm theo MaNV thì cần có một index trên cột MaNV
Vậy chúng ta có thể tạo một index tương tự như vậy nhưng trên cột MaNV không? Các bạn có nhớ index ở phần trước đã sắp xếp dữ liệu của bảng NhanVien theo cột ID. Nếu index mới này lại sắp xếp bảng theo cột MaVN vậy nó sẽ phá vỡ thứ tự của cột ID sao?
Đây chính là lý do trên một bảng chỉ có duy nhất một clustered index. Nếu bạn chạy câu lệnh tạo clustered index nữa SQL Server sẽ báo lỗi không thể tạo nhiều hơn một clustered index trên bảng NhanVien. Bên dưới là script tạo bảng NhanVien và insert dữ liệu được dùng cho ví dụ ở phần 1.
CREATE DATABASE NovaKhang;
GO
USE NovaKhang
GO
CREATE TABLE NhanVien
(
ID INT,
MaNV VARCHAR(12),
HoTen NVARCHAR(64),
Email VARCHAR(64),
NgaySinh DATE,
QueQuan NVARCHAR(64) ,
NoiCuTru NVARCHAR(64),
NgayGiaNhap DATE,
PhongBan TINYINT ,
QuanLy INT,
TTT CHAR(1800)
)
GO
INSERT INTO NhanVien(ID,MaNV,HoTen,Email,NgaySinh,QueQuan,NoiCuTru,NgayGiaNhap,PhongBan,QuanLy,TTT)
VALUES(1,'KD002',N'Nguyễn Văn Anh','nvanh@quantricsdulieu.com','1987-08-15',N'Long An',N'Quận 3','2010-04-12',3,16,'')
,(2,'AC005',N'Bùi Đình Thân','bdthan@quantricsdulieu.com','1988-06-12',N'Tây Ninh',N'Quận Thủ Đức','2009-07-21',1,16,'')
,(3,'KT007',N'Huỳnh Tấn Phong','htphong@quantricsdulieu.com','1992-03-11',N'TP.HCM',N'Quận 4','2012-08-10',2,11,'')
,(4,'AC011',N'Đào Thị Cúc Phương','dtcphuong@quantricsdulieu.com','1991-11-27',N'Bình Dương',N'Quận Bình Thạnh','2010-06-09',1,2,'')
,(5,'KT010',N'Trần Văn Bùi','tvbui@quantricsdulieu.com','1983-03-04',N'Đồng Nai',N'Quận 7','2015-01-02',2,12,'')
,(6,'KT001',N'Trần Tý','tty@quantricsdulieu.com','1984-01-15',N'Đắk Lắk',N'Quận 12','2009-09-17',2,16,'')
,(7,'AC007',N'Lê Thị Ngọc Hân','ltnhan@quantricsdulieu.com','1993-07-31',N'Lâm Đồng',N'Quận 10','2011-12-30',1,2,'')
,(8,'KD008',N'Phạm Ngọc Tuyến','pntuyen@quantricsdulieu.com','1996-12-17',N'TP.HCM',N'Quận Bình Thạnh','2014-07-15',3,1,'')
,(9,'KD010',N'Nguyễn Thị Như Quỳnh','ntnquynh@quantricsdulieu.com','1989-09-18',N'Lâm Đồng',N'Quận 9','2010-04-02',3,8,'')
,(10,'KD009',N'Phan Nguyễn Hoài Phúc','pnhphuc@quantricsdulieu.com','1987-03-16',N'TP.HCM',N'Quận Thủ Đức','2013-07-08',3,8,'')
,(11,'KT003',N'Phùng Quang Nguyên','pqnguyen@quantricsdulieu.com','1989-06-30',N'Bình Phước',N'Quận 5','2016-01-05',2,6,'')
,(12,'KT005',N'Ngô Xuân Dương','nxduong@quantricsdulieu.com','1991-11-20',N'Bình Phước',N'Quận 7','2017-02-21',2,6,'')
,(13,'NS01',N'Trần Nhật Du','tndu@quantricsdulieu.com','1982-07-30',N'Tây Ninh',N'Quận 8','2010-10-11',4,16,'')
,(14,'NS02',N'Nguyễn Công Lý','ncly@quantricsdulieu.com','1994-12-12',N'Tiền Giang',N'Quận Thủ Đức','2012-12-18',4,13,'')
,(15,'NS03',N'Huỳnh Quốc Đống','hqdong@quantricsdulieu.com','1989-04-18',N'Cần Thơ',N'Quận 12','2016-09-05',4,13,'')
,(16,'GD01',N'Nguyễn Công Bằng','ncbang@quantricsdulieu.com','1983-03-09',N'Cà Mau',N'Quận Thủ Đức','2009-07-21',NULL,NULL,'')
GO
CREATE UNIQUE CLUSTERED INDEX CIX_NhanVien ON NhanVien (ID ASC)
Cột TTT được thêm vào bảng NhanVien nhằm mục đích tạo ra kích thước một dòng đủ lớn để mỗi page chỉ có thể chứa 4 dòng. Bây giờ chúng ta thử tạo thêm một clustered index khác trên cột MaNV sẽ nhận được lỗi như hình bên dưới.
CREATE UNIQUE CLUSTERED INDEX CIX_NhanVien_MaNV ON NhanVien (MaNV ASC)

Hiển nhiên nhu cầu tìm kiếm dữ liệu của một ứng dụng là đa dạng, vậy nên ta cần nhiều hơn một index để có thể tìm kiếm trên nhiều cột khác nhau. Điều này có thể đạt được bằng cách sử dụng non-clustered index.
Nonclustered index
Để có thể sắp xếp theo thứ tự MaNV mà không làm mất đi thứ tự tập dữ liệu theo ID, SQL Server sẽ nhân bản dữ liệu của bảng NhanVien thành một tập khác rồi thực hiện sắp xếp và tổ chức index theo cột MaNV cho tập dữ liệu mới này. Đây cũng là sự khác biệt giữa non-clustered index và clustered index.
Việc nhân bản này sẽ không áp dụng cho tất cả các cột trong bảng NhanVien, mà chỉ thực hiện cho những cột được chỉ định trong câu lệnh tạo nonclustered index. Nói thì hơi khó hình dung, giả sử chúng ta tạo nonclustered index với câu lệnh như sau
USE NovaKhang
GO
CREATE UNIQUE NONCLUSTERED INDEX IX_NhanVien_MaNV ON NhanVien (MaNV)
Câu lệnh trên tạo index có tên là IX_NhanVien_MaNV với key là MaNV. Theo các bạn SQL Server sẽ nhân bản những cột nào? Hãy cùng khám phá bảng NhanVien sau khi thêm index này sẽ có hình dáng như thế nào dưới góc độ lưu trữ.
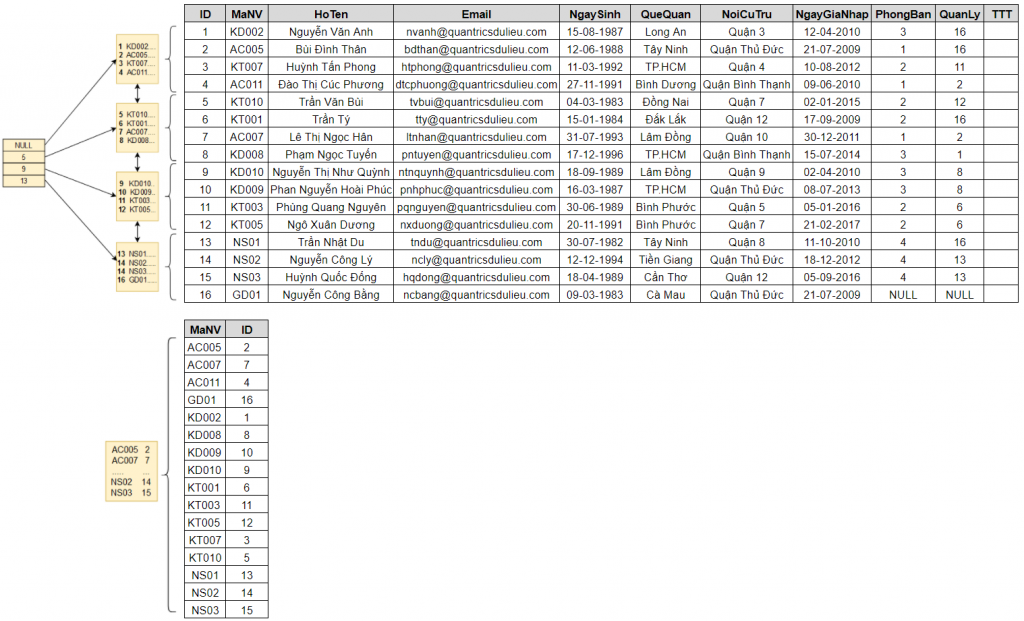
Bạn có thấy điều đặc biệt gì không? Nonclustered index IX_NhanVien_MaNV là một tập dữ liệu riêng biệt. SQL Server đã nhân bản và tạo ra một tập dữ liệu gồm hai cột MaNV và ID từ bảng dữ liệu gốc NhanVien. Chính vì vậy mà bạn thấy số dòng của hai tập này đều là 16 dòng.
Dữ liệu trong nonclustered index này được sắp xếp theo thứ tự của cột MaNV, và kích thước chỉ gói gọn trong 1 page. Nếu bạn mang thêm càng nhiều cột khác vào nonclustered index thì kích thước sẽ càng lớn. Đây là vấn đề chi phí lưu trữ khi tạo nonclustered index.
Bên cạnh đó, việc duy trì sự đồng nhất của dữ liệu vẫn cần phải đảm bảo trong quá trình vận hành. Điều này có nghĩa rằng mỗi khi SQL Server thay đổi giá trị MaNV ở bảng NhanVien nó cũng phải thay đổi tương dòng tương ứng trên nonclustered index.
Tương tự như vậy, khi thêm mới một dòng cho bảng (clustered index) cũng phải thêm cho index. Đây là vấn đề chi phí bảo trì để đảm bảo sự đồng nhất giữa hai index.
Mối quan hệ giữa clustered và nonclustered index
Câu lệnh tạo nonclustered index ở trên chỉ định mỗi cột MaNV là key. Nhưng khi khảo sát nội dung các pages của index này chúng ta thấy chúng chứa thông tin cột ID như hình 2.
USE NovaKhang
GO
SELECT object_id, name, index_id, type,type_desc
FROM sys.indexes
WHERE object_id = object_id('NhanVien')
GO
DBCC IND('NovaKhang','NhanVien',2)
GO
DBCC TRACEON(3604)
DBCC PAGE(12,1,472,3)
DBCC TRACEOFF(3604)
Đoạn script trên mình chạy lần lượt từng câu lệnh để lấy input cho câu lệnh phía sau. Câu lệnh đầu tiên để kiểm tra xem index_id của nonclustered index là bao nhiêu. Dùng giá trị đó cho câu lệnh DBCC IND() để xác định index này có những pages nào.
Tiếp đó chúng ta sẽ thấy chỉ có 1 page với pageID là 472, giá trị này được dùng để dump nội dung page ra bằng câu lệnh DBCC PAGE(). Kết quả ba câu lệnh trên được thể hiện trong hình bên dưới.

Các bạn có thấy trong result set cuối cùng có dữ liệu của hai cột MaNV và ID hay không? Điều này chứng tỏ mỗi dòng dữ liệu trong nonclustered index cần giữ giá trị clustered key. Giá trị này được dùng để quay ngược lại dòng dữ liệu tương ứng trên clustered index để lấy thêm dữ liệu các cột khác khi cần.
Câu lệnh select ở đầu bài của chúng ta cần lấy các cột ID, MaNV, TTT của nhân viên có MaNV = ‘KT001’. Nếu SQL Server truy cập nonclustered index để lấy dữ liệu thì sẽ không có thông tin cột TTT.
Lúc này nó cần dùng ID để quay về clustered index lấy thêm cột TTT của dòng tương ứng. Hành động này gọi là key lookup và nó tốn chi phí để thực hiện nên tổng chi phí chung của câu truy vấn sẽ tăng lên.
Nhân viên có mã KT001 có ID bằng 6. Sau khi lấy được giá trị này rồi SQL Server sẽ thực hiện thêm hành SELECT TTT FROM NhanVien WHERE ID = 6. Kết quả TTT này cộng với ID, MaNV từ nonclustered index sẽ cho ra kết quả cuối cùng và trả về cho người thực hiện truy vấn như execution plan dưới đây

Chúng ta có thể nhét thêm cột TTT vào nonclustered index không? Vì khi đó SQL Server chỉ cần sử dụng một index là đủ thông tin phục vụ cho câu truy vấn, tiết kiệm được chi phí key lookup. Có thể làm được điều này bằng cách sử dụng covering index, chúng ta hãy cùng tiếp tục tìm hiểu xem nó hoạt động thế nào.
Covering index
Covering index là khi nonclustered index có thể thỏa mãn tất cả các cột cần select của một câu truy vấn. Trong tình huống của chúng ta đó là có thể đáp ứng đủ các cột trong câu lệnh SELECT ID, MaNV, TTT FROM NhanVien WHERE MaNV = ‘KT001’.
Bạn có hai cách để nhét cột TTT này vào nonclustered index. Một là cho nó tham gia vào danh sách index key {MaNV, TTT}. Hai là thêm nó vào dữ liệu ở node lá (leaf node). Kĩ thuật covering index sử dụng cách thứ 2.
Bằng cách sử dụng mệnh đề INCLUDE khi tạo nonclustered index. Chúng ta có thể chỉ định những cột nào sẽ được thêm vào index đó. Script dưới đây xóa index hiện có và tạo lại để thêm cột TTT vào.
USE [NovaKhang]
GO
DROP INDEX IX_NhanVien_MaNV ON NhanVien
GO
CREATE UNIQUE NONCLUSTERED INDEX IX_NhanVien_MaNV ON NhanVien
(
MaNV ASC
)
INCLUDE([TTT])
Nếu lần này chúng ta chạy lại câu lệnh DBCC IND() ở trên sẽ thấy kết quả không chỉ là một page dữ liệu như hình 2. Vì cột TTT kiểu CHAR(1800) nên làm cho kích thước mỗi dòng tăng lên nhiều. Lúc này mỗi page chỉ có thể chứa 4 dòng.
Mình dump nội dung một pageID bất kì trên máy mình sẽ cho kết quả như hình bên dưới. Trên máy của bạn có thể có pageID khác và hãy nhớ chọn page có level = 0 (leaf node) mới thấy được nội dung đầy đủ.

Nonclustered index của chúng ta bây giờ đã có thêm cột TTT rồi. Như vậy câu lệnh select trên chỉ cần truy xuất một index IX_NhanVien_MaNV là đủ. Hãy nhìn execution plan dưới đây.

Với số lượng page tăng lên như vậy lúc này nonclustered index của chúng ta sẽ trông như hình dưới

Bây giờ nonclustered index của chúng ta đã có thêm 1 level. Kích thước dòng hoặc số lượng dòng càng tăng thì sẽ làm tăng index level.
Qua bài viết này chắn bạn đã nhận ra mỗi một nonclustered index bạn tạo ra sẽ tốn thêm một vùng không gian đĩa để lưu trữ ngoài kích thước của bảng. Kích thước key và số lượng cột thêm vào index sẽ ảnh hưởng đến kích thước của index và đặc biệt tốn chi phí bảo trì index cho mỗi hành động insert/update/delete. Bạn cần cân nhắc để đảm bảo index tạo ra được sử dụng hiệu quả cho các câu truy vấn.
